
Optimal Data Processing: Membangun Arsitektur Data yang Cepat, Efisien, dan Handal
Di era transformasi digital saat ini, data bukan lagi sekadar aset statis, melainkan bahan bakar utama bagi pengambilan keputusan strategis. Namun, tantangan terbesar bagi para pengembang dan data engineer bukan lagi tentang bagaimana mengumpulkan data, melainkan bagaimana memprosesnya dengan cara yang paling optimal. Menggunakan arsitektur tradisional seringkali terasa berat dan lambat saat berhadapan dengan volume data yang besar. Solusi modern kini bergeser pada integrasi teknologi yang ringan namun bertenaga, seperti kombinasi Flask, DuckDB, dan format penyimpanan Parquet.
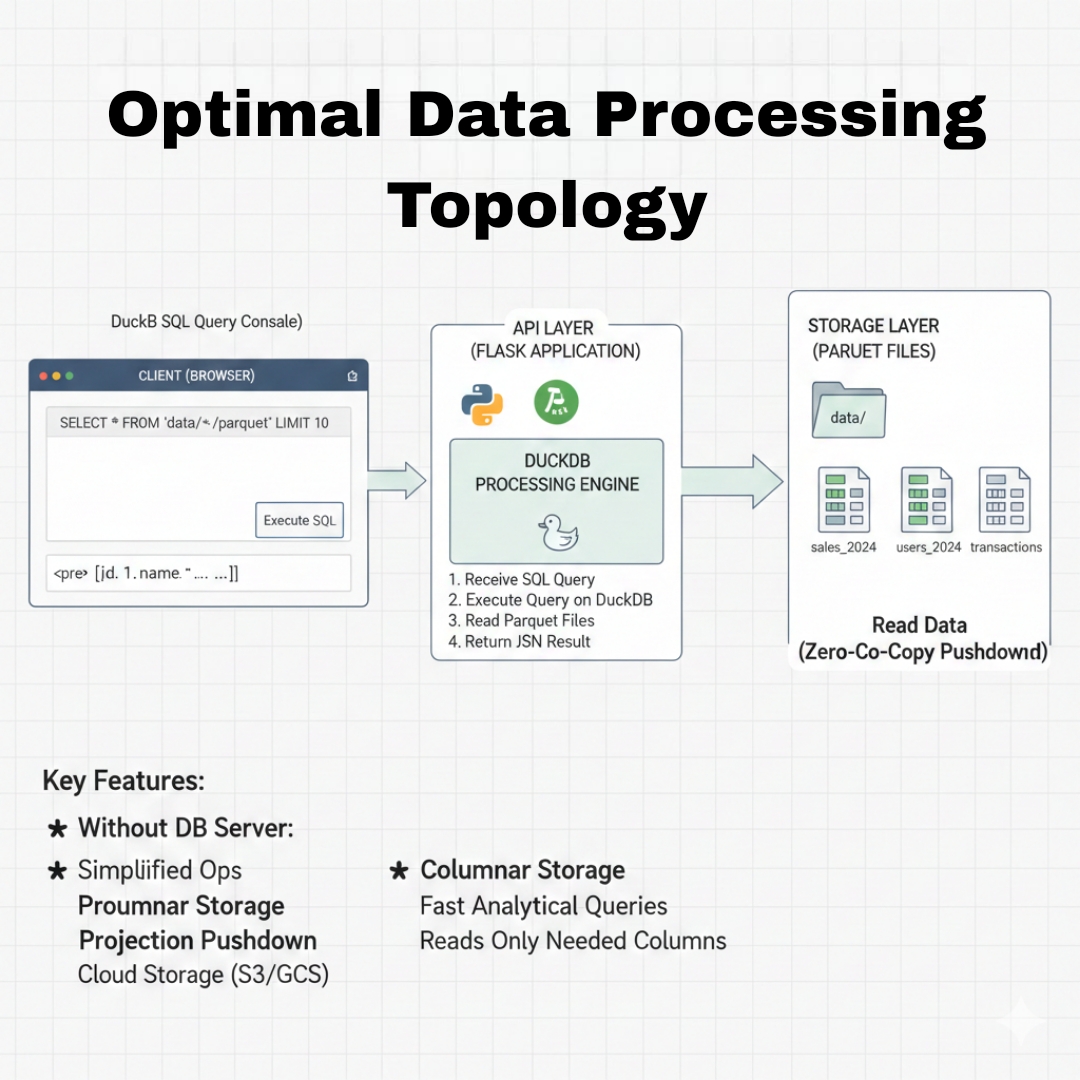
Topologi ini menawarkan paradigma baru dalam pengolahan data di server (seperti Ubuntu Server 24 LTS) yang mampu memenuhi tiga pilar utama: kecepatan tinggi, efisiensi sumber daya, dan keandalan sistem.
Pilar Pertama: Kecepatan (Speed) dalam Analisis Data
Kecepatan adalah mata uang utama dalam pengolahan data. Arsitektur konvensional biasanya melibatkan perpindahan data yang kompleks dari database server ke application server melalui jaringan yang seringkali menjadi hambatan (bottleneck). Dengan menggunakan DuckDB, hambatan ini dieliminasi secara signifikan.
DuckDB dirancang sebagai mesin OLAP (Online Analytical Processing) yang bersifat in-process. Artinya, DuckDB berjalan di dalam proses aplikasi Flask Anda, bukan sebagai layanan terpisah yang membutuhkan koneksi TCP/IP. Ketika seorang pengguna memasukkan query SQL melalui browser, Flask langsung mengeksekusi perintah tersebut menggunakan engine DuckDB yang mengakses data secara lokal.
Kecepatan ini semakin didorong oleh penggunaan format Parquet. Tidak seperti CSV yang harus dibaca baris demi baris secara sekuensial, Parquet menyimpan data secara kolumnar. Jika Anda menjalankan query “SELECT total_penjualan”, DuckDB hanya akan membaca kolom tersebut dari disk dan mengabaikan kolom lainnya. Inilah yang disebut dengan Projection Pushdown, sebuah teknik yang secara drastis memangkas waktu I/O dan mempercepat respon query hingga hitungan milidetik, bahkan pada dataset berukuran gigabyte.
Pilar Kedua: Efisiensi (Efficiency) Biaya dan Sumber Daya
Efisiensi dalam “Optimal Data Processing” berarti mendapatkan hasil maksimal dengan penggunaan perangkat keras yang minimal. Di sinilah Ubuntu Server 24 LTS menjadi fondasi yang sempurna. Mengoperasikan database besar seperti PostgreSQL atau BigQuery memerlukan biaya langganan atau manajemen infrastruktur yang rumit. Sebaliknya, kombinasi DuckDB dan Parquet memungkinkan kita membangun “Data Warehouse tanpa server”.
Secara operasional, efisiensi ini terlihat dari dua sisi:
- Penyimpanan Kolumnar: Parquet memiliki algoritma kompresi yang sangat canggih (seperti Snappy atau Zstd). File data yang tadinya berukuran 10GB dalam format CSV seringkali menyusut menjadi hanya 1-2GB dalam format Parquet tanpa kehilangan informasi sedikitpun. Ini menghemat ruang disk pada server Ubuntu Anda.
- Manajemen Memori: DuckDB dikenal sangat cerdas dalam mengelola RAM. Ia menggunakan teknik vectorized query execution, di mana data diproses dalam blok-blok kecil yang masuk ke dalam cache CPU. Hal ini memastikan bahwa server Anda tidak mengalami crash akibat kehabisan memori meskipun sedang menangani dataset yang lebih besar dari kapasitas RAM fisik.
Bagi pengembang, efisiensi juga berarti kemudahan pengembangan. Dengan Flask, Anda hanya memerlukan beberapa baris kode untuk membuat interface berbasis web yang mampu menjalankan query SQL mentah. Tidak ada kebutuhan untuk skema database yang kaku di awal (schema-on-read), memberikan fleksibilitas tinggi bagi pengembang untuk bereksperimen dengan data cleansing.
Pilar Ketiga: Keandalan (Reliability) dan Integritas Data
Sistem yang cepat dan efisien tidak akan berarti jika tidak handal. Keandalan dalam topologi ini dibangun melalui kesederhanaan. Semakin sedikit komponen bergerak (moving parts) dalam sebuah sistem, semakin rendah kemungkinan terjadinya kegagalan. Karena DuckDB bersifat serverless dan berbasis file tunggal, Anda tidak perlu khawatir tentang layanan database yang mendadak mati atau kegagalan koneksi jaringan antar-server.
Dalam konteks Data Cleansing, keandalan sistem ini memastikan bahwa proses transformasi data—seperti standarisasi format tanggal, penanganan nilai kosong (null handling), hingga pembersihan duplikat—dapat dilakukan secara atomik. DuckDB mendukung transaksi ACID, yang menjamin bahwa jika sebuah proses pembersihan data gagal di tengah jalan, database tidak akan berada dalam kondisi korup.
Selain itu, menjalankan arsitektur ini di Ubuntu Server 24 LTS memberikan lapisan keamanan dan stabilitas jangka panjang. Dengan dukungan jangka panjang (LTS), server Anda akan menerima pembaruan keamanan rutin, memastikan bahwa API Flask yang mengekspos data Anda tetap terlindungi. Untuk meningkatkan keandalan, pengembang dapat menerapkan skema staging:
- Raw Layer: Data asli tersimpan di folder ‘bronze’.
- Cleaned Layer: Data hasil pemrosesan SQL disimpan di folder ‘silver’ dalam format Parquet yang sudah teroptimasi. Hal ini memastikan bahwa data asli selalu tersedia jika diperlukan proses ulang, menciptakan sistem yang tangguh terhadap kesalahan manusia.
Kesimpulan: Masa Depan Pengolahan Data
Mengintegrasikan Flask sebagai antarmuka, DuckDB sebagai mesin pemroses, dan Parquet sebagai media penyimpanan adalah manifestasi nyata dari Optimal Data Processing. Topologi ini membuktikan bahwa kita tidak selalu membutuhkan infrastruktur awan yang mahal untuk melakukan analisis data skala besar.
Dengan kecepatan yang dihasilkan dari eksekusi vectorized, efisiensi dari penyimpanan kolumnar, dan keandalan dari arsitektur in-process di atas Ubuntu Server, siapa pun kini dapat membangun platform analitik yang hebat. Inilah solusi bagi para praktisi data yang menginginkan performa tinggi tanpa harus mengorbankan kesederhanaan sistem. Di masa depan, seiring dengan semakin besarnya volume data dunia, pendekatan yang mengutamakan efisiensi dan kecepatan seperti inilah yang akan terus relevan dan menjadi standar industri.
